
Contextual text mining methods extract information from documents, live data streams and social media. In this project, thousands of tweets by users were extracted to generate sentiment analysis scores.
Sentiment analysis is a common text classification tool that analyzes streams of text data in order to ascertain the sentiment (subject context) of the text, which is typically classified as positive, negative or neutral.
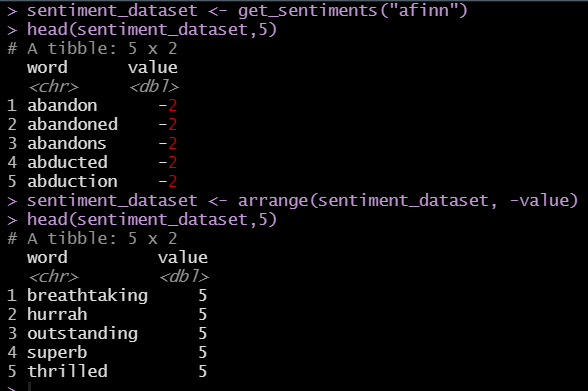
In the R sentiment analysis engine, our team built, the sentiment score has a range of .-5 to 5. Numbers within this range determine the the change in sentiment.
| Sentiment | Score |
| Negative | -5 |
| Neutral | 0 |
| Positive | 5 |
Sentiment Scores are determined by a text file of key words and scores called the AFINN lexicon. It’s a popular with simple lexicon used in sentiment analysis.
New versions of the file are released in source repositories and contains over 3,300+ words with scores associated with each word based on its level of positivity or negativity.
Twitter is an excellent example of sentiment analysis.
An example of exploration of the sentiment scores based on the retweets filtered on the keywords:
- Trump
- Biden
- Republican
- Democrat
- Election
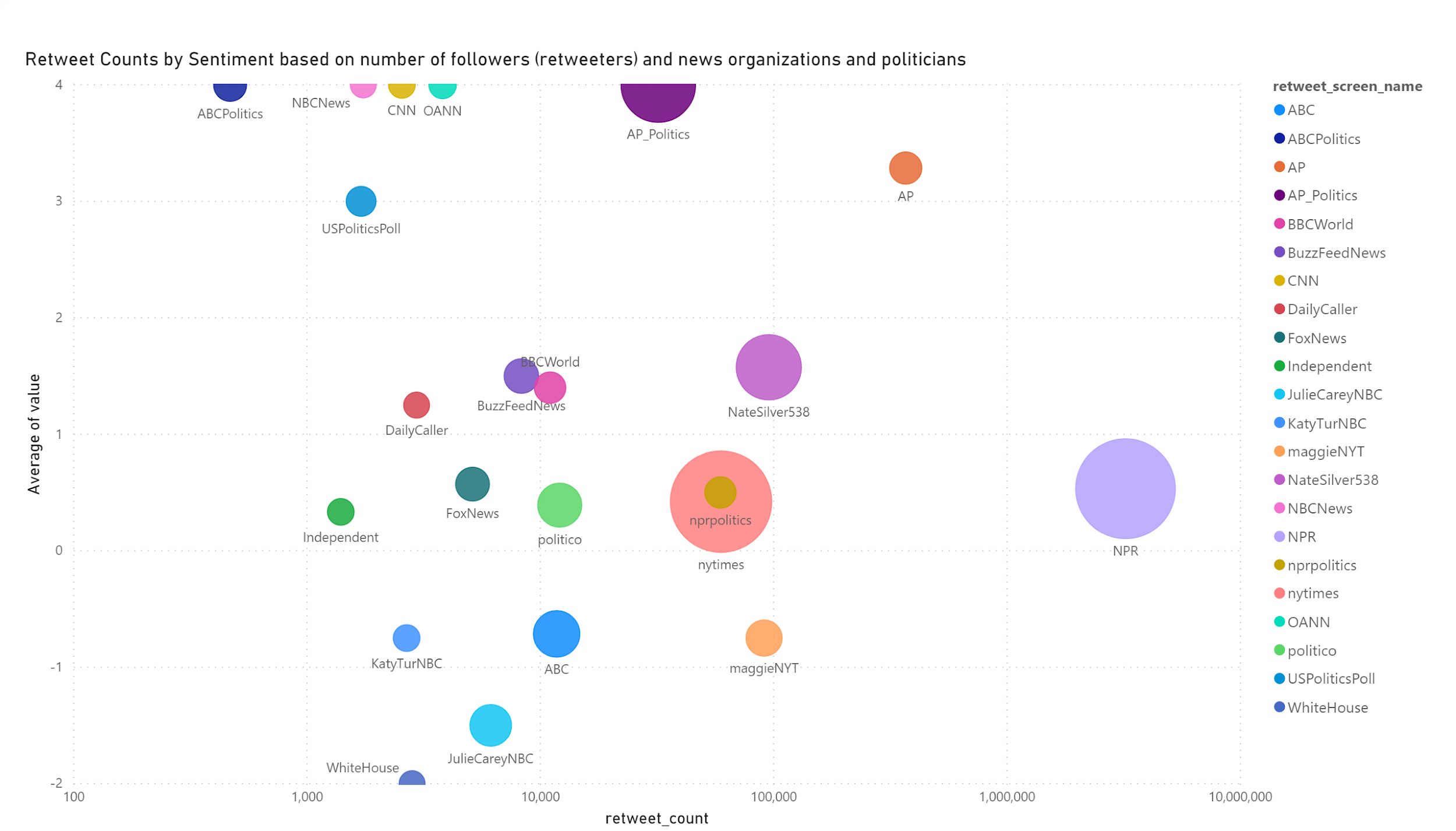
The data was created using a sentiment engine built in R. It is mostly based on the political climate in the United States leading up to and after the 2020 United States election.
Each bubble size represents the followers of user who’ve retweeted. The bubble size gives a sense of the influence of those users (impact). The Y-axis is the sentiment score, the X-axis represents the retweet count of the bubble name.
“Impact” is a measure of how often a twitter user is retweeted by users with high follower counts.
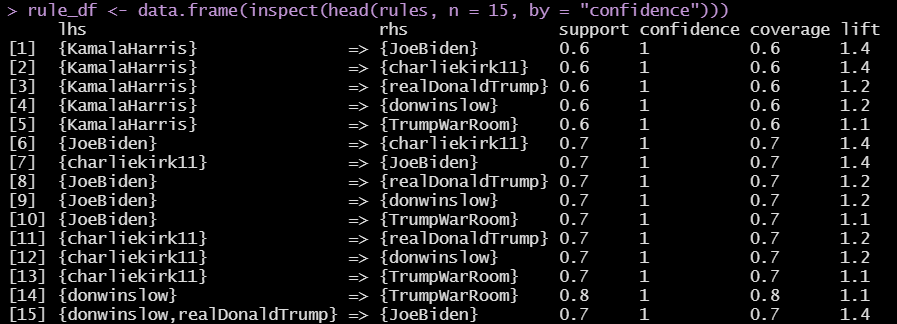
Using the Apriori Algorithm, you can build a sentiment association analysis in R. See my article on Apriori Association Analysis in R.
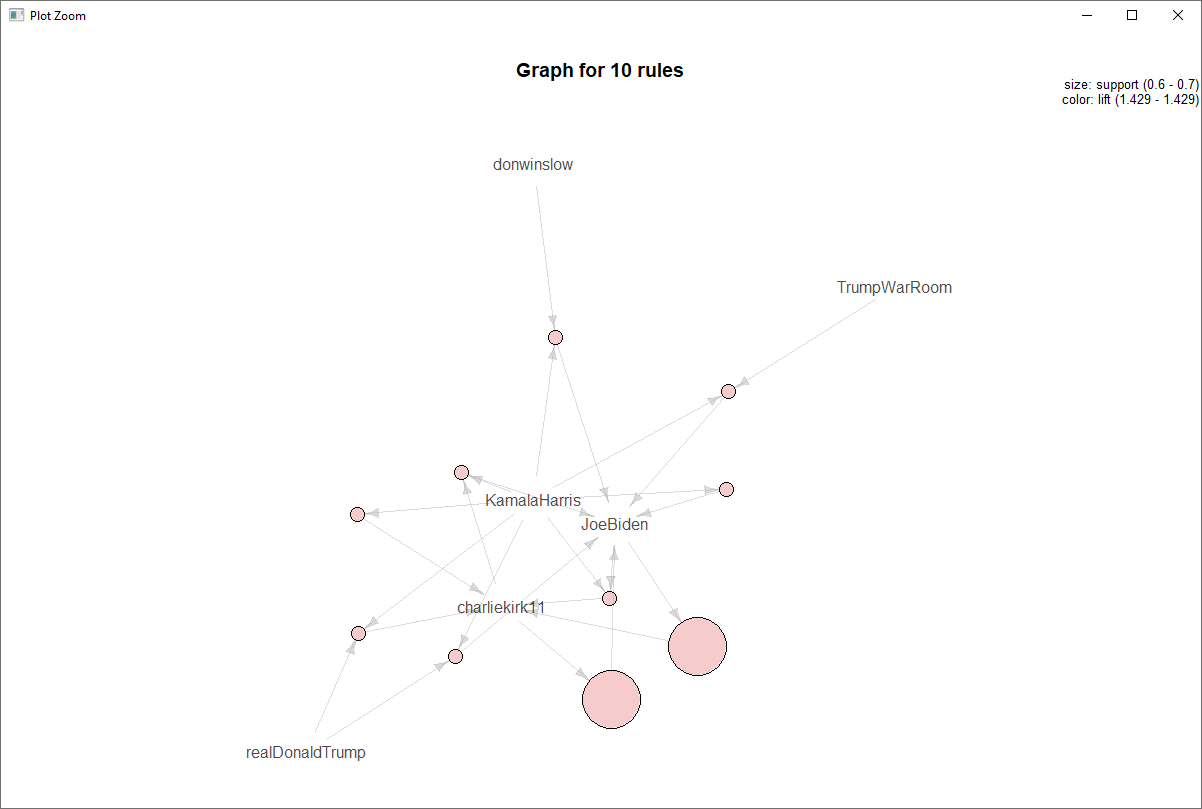
Applying the Apriori algorithm. using the single format, we assigned our transactions as the sentiment score and We assigned items_id as retweeted_screen_name.
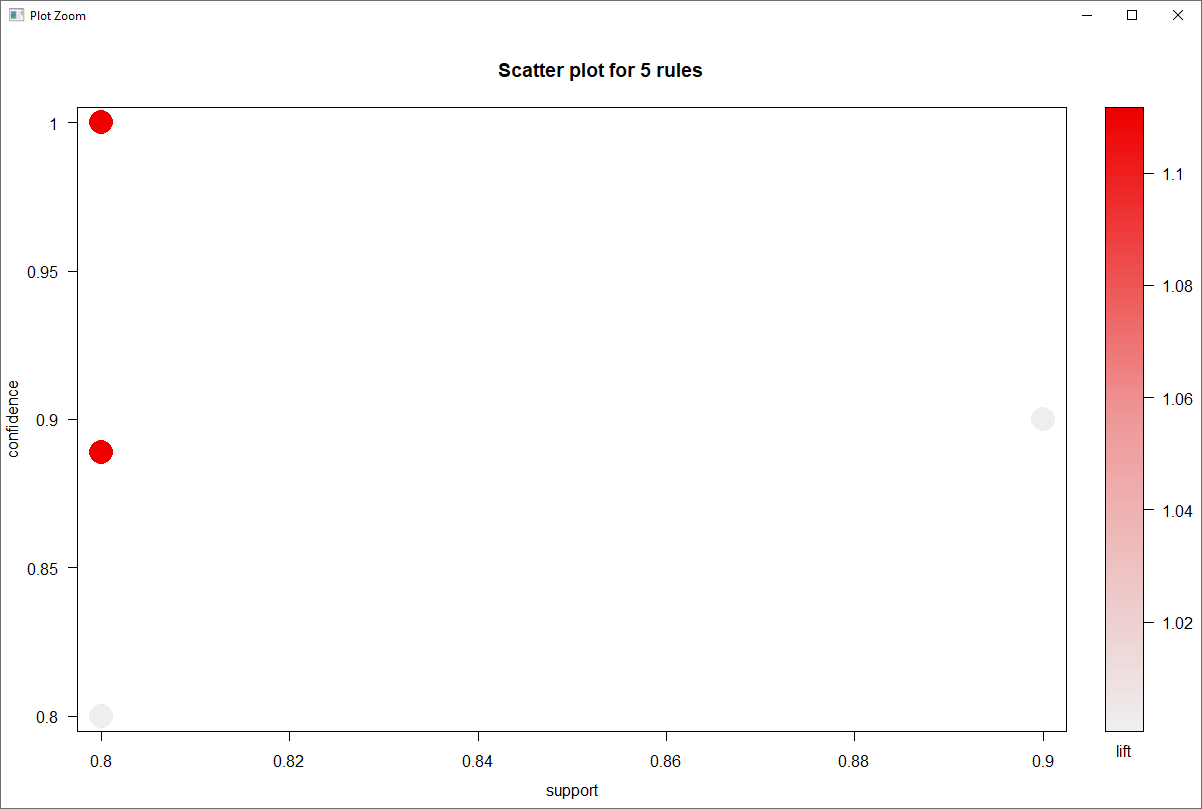
This is the measure the association between highly retweeted accounts and their associations based on sentiment scores (negative, neutral, positive). Support is the minimum support for an itemset. Minimum support was set to 0.02.
The majority of the high retweeted accounts had highly confident associations based on sentiment values. We then focused on the highest confidence associates that provided lift above 1. After removing redundancy, we were able to see the accounts where sentiment values are strongly associated between accounts.
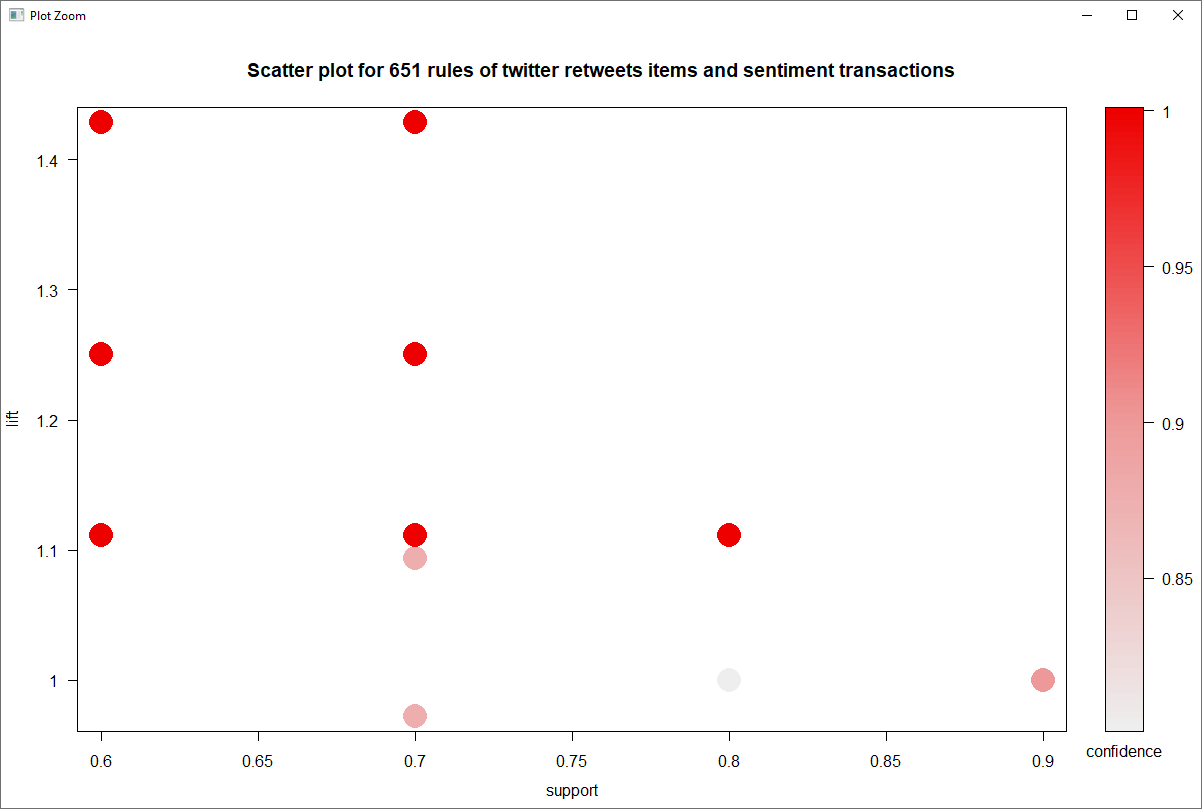
According to the scatter plot above, we see most of the rules overlap, but have very good lift due to strong associations, but also this is indicated by the limited number of transactions and redundancy in the rules.
The analysis showed a large number of redundancy, but this was mostly due to the near nominal level of sentiment values. So having high lift, a larger minimum support and .removing redundancy find the most valuable rules.
Pingback: Twitter is a Social Media Engagement Multiplier | Data Flux
Pingback: How to Improve your Twitter Followers Count (Part I) | Data Flux