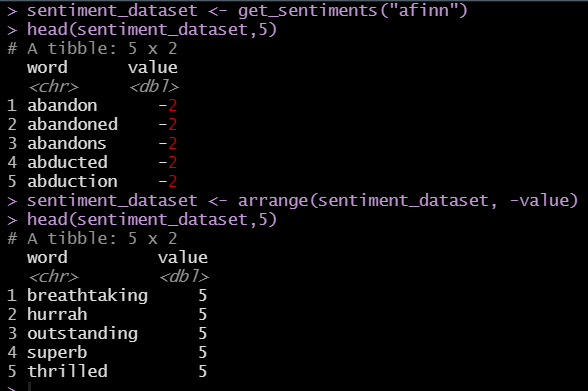
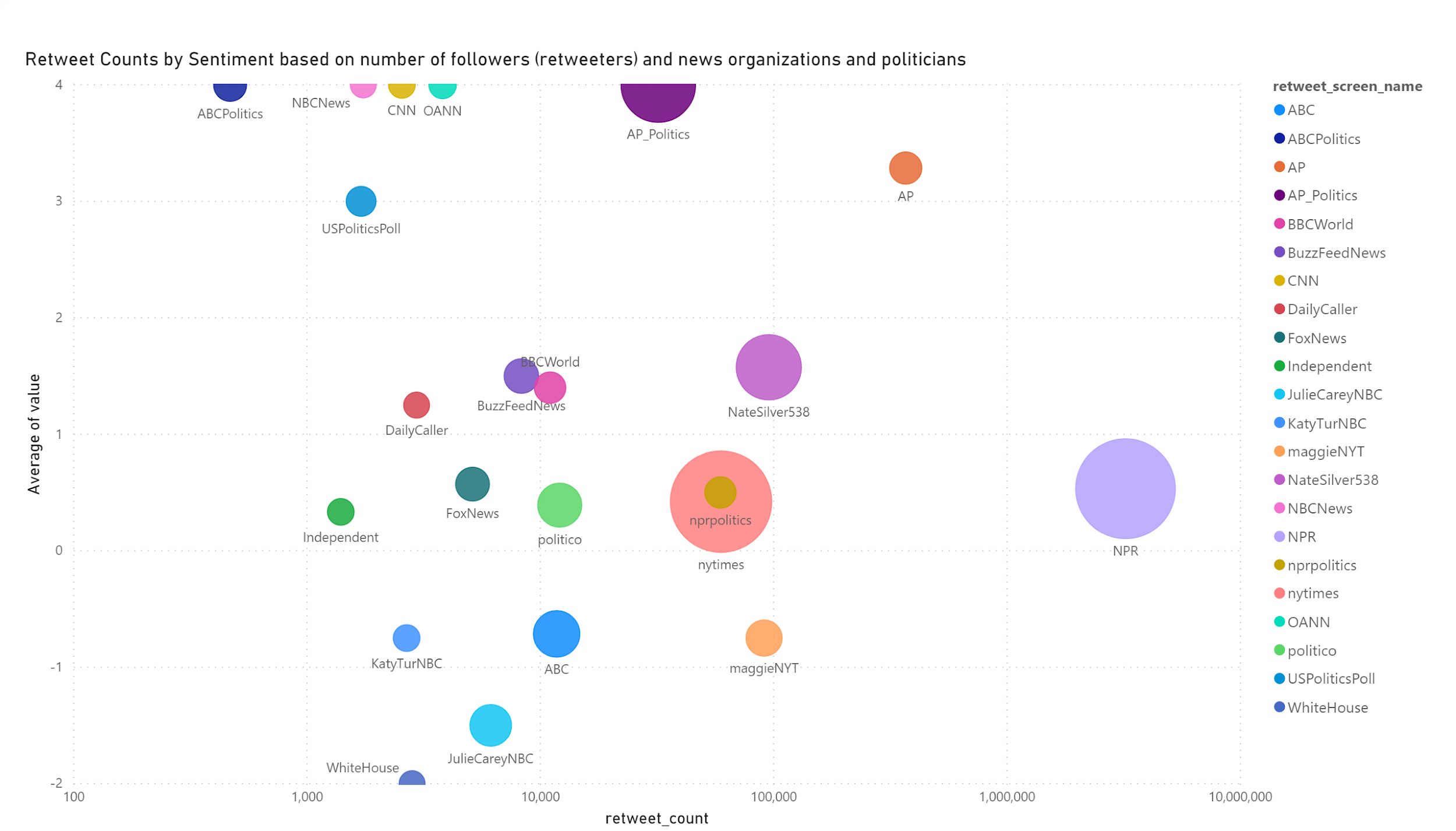
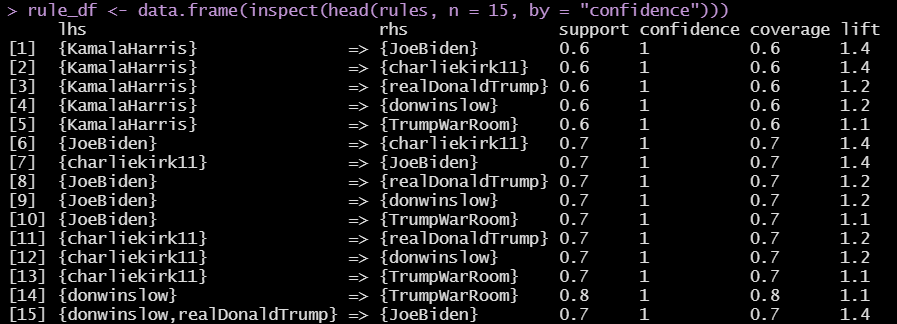
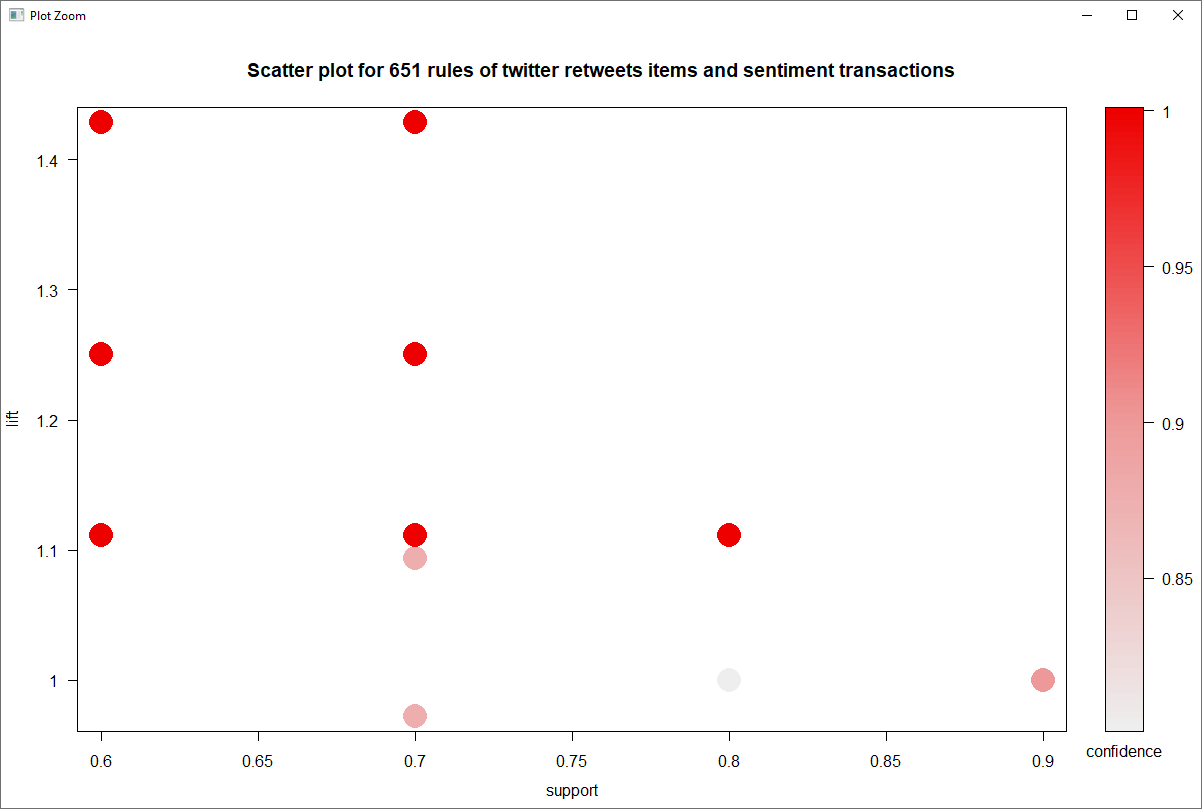
Executive Summary
The Great Recession was one of the most turbulent economic periods of the past eighty years. It was a global economic recession that impacted hundreds of banks, some of them responsible for financing the Gross Domestic Product (GDP) of entire countries. During the recession, many banks closed due to the speculation that flooded into the real estate market with new banking products that gave loans to millions of subprime consumers. This allowed people to take out loans with low interest rates but very complicated terms that made it much easier to end up in foreclosure proceedings. During this period, home mortgages defaults skyrocketed in many states further depressing the market. This in turned caused many people to lose their life savings as well as their home and jobs. It is now popularly considered the longest period of economic downturn since the Great Depression of the 1930’s.
Since the great recession, many financial regulations and policies were put in place to prevent it from happening in the future. The most popular of these were the Dodd-Frank Wall Street Reform and Consumer Protection act, also known as part of the Emergency Economic Stabilization Act, passed by Congress that amended many existing regulations to make it much easier to protect consumers by creating new government agents tasked with overseeing aspects of the financial banking system. When Donald Trump was elected President in 2016, he signed a new law rolling back significant portions of the law.
One of the upsides of the recession is how much articles, books, and analysis done before, during and after the financial crisis. This is of significant importance, because understanding how the financial markets got to that point in 2008, will help consumers better understand and better prepare for what not to do. Another added benefit of understanding this period of time, is how many banks gambled with risky financial products, only to lose all the money it had. Many consumers are now educated enough to know take on these risky loans, and banks scrutinized mortgage applications more closely. During the recession, Inflation in the market ballooned housing prices until there was an inevitable crash.
The following report details state-by-state the impact of this period on the housing market, consumers, and overall housing values to give the audience a better understanding of quantitative impact monthly and yearly. I will also show visualizations of housing prices detailing the loss of housing value, as a result causing many borrowers to be “under water” with their home mortgages. The report will also focus on four states (North Carolina, California, Massachusetts and Florida) and impact on job losses and employment each month during the period of this recession.
Charts and Graphs
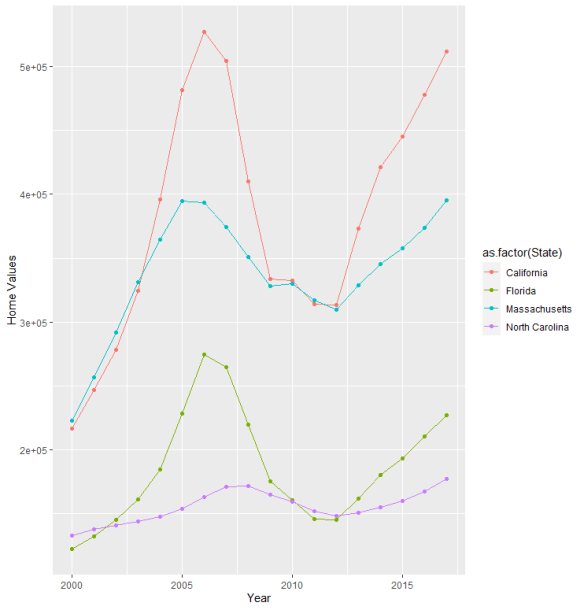
One the most crippling results of the Great Recession was on consumers. Many consumers lost their homes as the downturn rippled throughout the country. Figure 1 shows an aggregate picture of housing prices between 1996 and 2017 for the four states analyzed. Notice how there was a steep growth in housing values and then a sudden drop during the period during and shortly after the recession. Housing values would eventually rise again, but trillions of dollars of equity would be lost, with many communities not recovering.

Figure (1): Average condo home prices in Florida and California were impacted more heavily by the economic downturn and drop in housing prices compared to North Carolina and Massachusetts. Source Zillow.com
The impact of housing prices for California and Florida do not really come as a surprise. Both of these states tend to have housing values greater than states where the cost of living is less. Also, these states tend to have residents with higher incomes than the general population (retirees and white-collar workers).
When compared to the entire country, several states saw changes in the percentage of income compared to the change in home ownership. This is an indication of how well some states weathered the economic downturn among their populations. States such as California, Nevada, and many areas in the southwest saw a slow precipitous drop in home ownership along with a drop in income (with the exception of Utah). Many states in the south did see drops in home ownership, but on average, the incomes of their populations remained the same. North Carolina, for instance, saw no net loss of income, but an increase in home ownership. States such as Nevada saw both large losses in income for their population as well as loss in home ownership in Figure 2. Nevada was particularly hit hard by the economic recession.

Figure (2): A heat map of the country comparing changes in income and home ownership. Source GeoFred. https://geofred.stlouisfed.org/
The nest visualization shows the average unemployment rate. This increased significantly during and after the great recession. In figure 3, it shows how this unemployment became more long than the period of the recession itself, showing the economic impact on families beyond the initial wave of economic decline.

Figure (3): Line graph of unemployment rates. Source U.S. Bureau of Labor Statistics. https://www.bls.gov/cps/tables.htm
Conclusion
What these graphs show us is how, during the economic downturn, there was not only an impact on the housing market, but also income growth and unemployment. Showing the scope and depth of the problem. One of the unfortunate results of the recession was that many banks considered “too big to fail” received government funding to bail them out, and many homeowners and consumers were left to fill the blunt of the economic recession on their own.